Contents
Designing an OO System
There are potentially many activities involved in the full lifecycle of an OO
System. Some people will start with an Analysis Model, which describes 'the
problem'. From this, they will create a Design Model, which describes 'the
solution', and then go on to develop from that design, with changes made as the
implementation and the local change control system require. Finally, there will
be the Implementation model of the system as developed - which hopefully is
pretty close to the Design model. All these models will probably use UML and
have some number of backing documents.
In this process the Models are usually more or less inviolate: they may change,
but only with great effort and reluctance.
Another approach is to skip the Analysis Model and go straight to the Design
Model. This model provides a start for development but is viewed very much as a
perishable entity: it is valid for about one hour after it's finished and must
then be viewed (if kept at all) with suspicion. This is much closer to my view
of Models: they communicate something which is valid now and as we all know
better ideas come along later, or constraints we hadn't thought of appear, or
the user changes his mind about something.
One thing I do like to do, though, is to create a fairly high-level model at the
start. This will show me the major areas that I'm going to have to implement at
the very least. I am likely to go through several iterations to get to a model
I am happy with. As I get more experienced, or know more about the problem
domain, this initial model looks more and more like the final implementation -
as long as the user doesn't stick his oar in!
The purpose of this exercise is to take some requirements and produce this
initial model.
There are a number of ways to get from the requirements to an initial model. The
most common one is pretty na�ve, in a way, but does provide a way to start.
This approach involves going through the requirements and making a list of all
the nouns. After removing duplicates and making plurals singular each noun
remaining is a candidate Class. This is called Textual Analysis:
-
Nouns and Noun Phrases become classes and attributes
-
Verbs and Verb Phrases become methods and associations
-
Possessive Phrases indicate that nouns should be attributes not classes
Next, look through this list and remove items that are unnecessary (redundant or
irrelevant), or incorrect (too vague, or they represent things outside the
scope of the model, or they actually represent actions).
The requirements with nouns highlighted:
| The system will record animals, their names and
owner's names, and the results of genetic tests made on animals.
These results come in the form of a 5-character string describing
the expression of an allele for each allele tested; there
will be 5 or 6 alleles per animal.
A technician will be able to call up the results for one animal
and ask the system to match its test results, via an algorithm
to be supplied, against other results in the database and display
the matching animals and their test results. The technician
will then select from this list animals which are, by his
interpretation of the tests, related to the original animal. This relationship
will be stored for later enquiries.
|
Our initial pass gives us:
| 5-character string |
| Algorithm |
| Allele |
| animal (and matching animal and original animal) |
| database |
| expression |
| genetic test |
| list |
| name |
| Owner (owner's name) |
| Relationship |
| result (and test result) |
| system |
| technician |
Of these:
-
Database should be eliminated. We may end up with a database class
encapsulating some form of storage, but right now it's too nebulous to be a
class.
-
List is either a GUI object - thus irrelevant at the moment - or a collection
of animals, and so can be excluded either way.
-
System is too nebulous.
-
Technician is an Actor and so may appear on use case diagrams, but does not, so
far, merit being a class.
-
Algorithm is pretty nebulous: it's going to have to be expanded on but it will
definitely be there; it stays.
-
5-character string is the same as expression and so we'll drop it as expression
is a more descriptive word.
-
Name and Owner are clearly attributes of an animal.
This gives us the following list of candidate classes, with class names given:
| Class Name |
Base Noun |
| RelativeMatcher |
Algorithm |
| Allele |
Allele |
| Animal |
Animal |
| AlleleExpression |
Expression |
| GeneticTest |
genetic test |
| RelatedAnimal |
relationship |
| TestResult |
Result |
It's important not to spend too long on this activity, otherwise you'll get
bogged down in analysis-paralysis. Once you're read and assimilated the
requirements document I would guess half a day to a day to get to this point is
enough on all but huge projects. We aren't trying to get every class, just the
most important ones from which the others will appear as we get into more
detailed analysis. By the time you've assimilated the results you possibly have
an idea of the broad shape of the system anyway; I usually skip this step as
I've effectively done it in my head, and go straight on to the next.
First-cut diagram
This is where you write out the relationships between the classes you've
discovered. I start by showing the connections between the classes and their
cardinality: for instance, one Animal will have 0 or many GeneticTests (the
requirements at this stage don't say anything about this, so I'll assume what
seems likely to me and clear it up later).
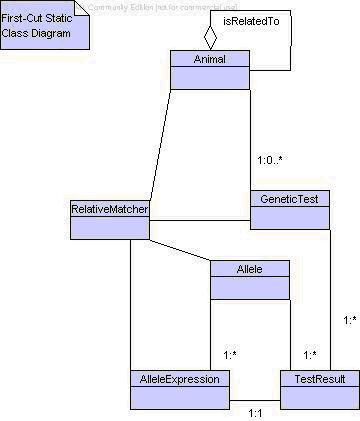
One important thing to note is that this diagram does not include the
RelatedAnimal class but does have a relationship from Animal to itself. This is
the 'Open Diamond' relationship, indicating that one animal may have a
relationship to many Animals. I have labelled this 'isRelatedTo'. This
self-relationship does away with the RelatedAnimal class for the moment: all we
know about the relationship is that it exists; we don't have any more
information about it to store (e.g. what the relationship actually is such as
'mother' and so on) and so it's redundant.
There are two questions which this diagram shows up:
-
TestResult and AlleleExpression have a 1:1 relationship. Are they actually the
same thing? I suspect that they are, and without further information would
merge them.
-
RelativeMatcher is linked to every class, given that TestResult and
AlleleExpression are the same. (I haven't bothered to put cardinalities in.)
This is worrying: it's starting to look like a
God-object. When we get the details of the algorithm we may be able to
split this up a bit. It's something to keep an eye on.
This diagram would also show any generalisation (inheritance) relationships I
can find. Since I can't find any, I show none.
The cardinalities I have put in are guesses. In this simple example I am fairly
sure of them, but in a larger system I might not be. They can be missed
entirely, but I find them useful. In any case, don't spend a lot of time on
them at this stage.
Another thing to look out for is Many-Many relationships: These can often cause
problems which can be solved with the addition of an 'Association' class. For
example, a contractor can work for many companies, and a company can have many
contractors. Introduce an Association class called Contract which has one
Company and one Contractor. Do this now if you are sure of the cardinalities.
My Top 10 mistakes
This is similar, though not identical, to a list in
Use Case Driven Object Modeling with UML by Doug Rosenberg and Kendall
Scott. The differences exist because the list is, after all, my mistakes.
-
10: Don't spend too much time assigning cardinalities to relationships, believe
that those you have assigned are correct, or insist that there must be a guess
for every association
-
9: Don't do noun and verb analysis so exhaustive you pass out on the way
-
8: Don't optimise your design for reusability before ensuring you've met the
users' requirements
-
7: Don't debate whether to use aggregation or composition (open or closed
diamonds) for each part-of association
-
6: Don't use hard-to-understand names for classes. For example,
AlleleExpression is preferred to FiveOrSixCharacterString. Obvious, but very
important. Always use
Intention-revealing names even if they're long!
-
5: Don't go directly to implementation constructs such as namespaces, or public
or internal modifiers.
-
4: Don't create a one-one relationship between database tables and classes if
one source of information is a legacy database.
-
3: Don't go for premature-patternisation, building cool constructs which may
have little or no relationship to the eventual solution. For instance, I think
that RelativeMatcher may end up as a Mediator with a Strategy. It's fine for me to think that (geeky daydreams - yes!), but not for me to start
planning it in any way (how many of your dreams do you act on?).
-
2: Don't get attached to your solution yet.
-
1: Don't truly believe a pixel of it! It's a snapshot of your thinking based
on not enough information. It's a place to start from which you can find
what really needs to be done (which may include starting from somewhere else entirely,
if you can't get there from here).
Looking at the final diagram below I've not done too badly against these rules. I've got
too many cardinalities, true, but I don't trust them so it's OK really. Honest!
The more important rules I think I've done OK on.
Although I've used a diagramming tool to produce the diagram, I would probably
not do so yet in practice. A sheet of paper is much easier to throw away, and
it's likely that I will throw away several versions of it before I'm happy.
Here's the paper version I did:
Second-Cut: Methods and Attributes
One thing I'll mention here, and won't again, is that I always assign an OID to
each object. This may be a GUID or an int assigned by an SQL Identity column
(I'm using GUID more and more these days). Just assume that that every class
has a read-only OID property.
Similarly, I'm not assuming anything about a storage mechanism as yet. In fact,
I'm ignoring it. Obviously there must be some way to get data into and out
of storage but unless the specification explicitly states that something must
be stored or loaded and it has 'interesting' properties I'm totally ignoring
that problem. It's an implementation detail and I'm not worried about it for
this iteration of the design.
In the following TestResult has become AlleleExpression
The requirements with verbs and possessive nouns highlighted:
|
The system will record animals, their names and owner's names,
and the results of genetic tests made on animals. These results come
in the form of a 5-character string describing the expression of an
allele for each allele tested; there will be 5 or 6 alleles per animal.
A technician will be able to call up the results for one animal and ask
the system to match its test results, via an algorithm to be supplied,
against other results in the database and display the matching animals
and their test results. The technician will then select from this list
animals which are, by his interpretation of the tests, related to
the original animal. This relationship will be stored for later
enquiries.
|
Our initial pass gives us
| record |
| name |
| owner's name |
| made |
| come |
| describing |
| tested |
| be able to call up |
| ask |
| to match |
| to be supplied |
| display |
| select |
| interpretation |
| related to |
| be stored |
At this stage, I'm labelling attributes, properties, and methods as
methods or properties almost arbitrarily. What they actually are
is an implementation artefact. What we're doing is creating the high-level
interface for each class, not a program spec.
Of these:
| Verb |
Comments |
Outcome |
| record |
This means we have to store the Animal in some way, and tests etc |
Animal.Save(), GeneticTest.Save(), AlleleExpresion.Save() |
| name |
Method |
Animal.Name |
| owner's name |
Method |
Animal.OwnersName |
| made |
Association |
Animal to GeneticTest |
| come |
Noise. |
Ignore |
| describing |
Association and method |
Association GeneticTest to AlleleExpression and AlleleExpression.Description |
| tested |
Association |
Allele to GeneticTest or AlleleExpression |
| be able to call up |
A GUI Requirement |
Ignore for now |
| ask |
A GUI requirement |
Ignore for now |
| to match |
Possibly a method on Animal |
Animal.MatchRelatives() |
| to be supplied |
Irrelevant; just says we don't know details of RelativeMatcher |
But not to schedule - this goes into Risk Analysis |
| display |
A GUI Requirement |
Ignore for now |
| select |
A GUI Requirement |
Ignore for now |
| interpretation |
Out of scope |
This is an action the technician performs, not our system. |
| related to |
Association of Animal to Animal |
Animal.Relatives() |
| be stored |
Covered by Animal.Save() |
Could be left out |
The associations we have discovered also imply attributes and methods. Here we
must pin down cardinality and navigability. Usually this will involve
discussions with the client. These discussions are fed back into the first cut
diagram as more data is discovered, and classes and associations are clarified.
The model I have so far is:
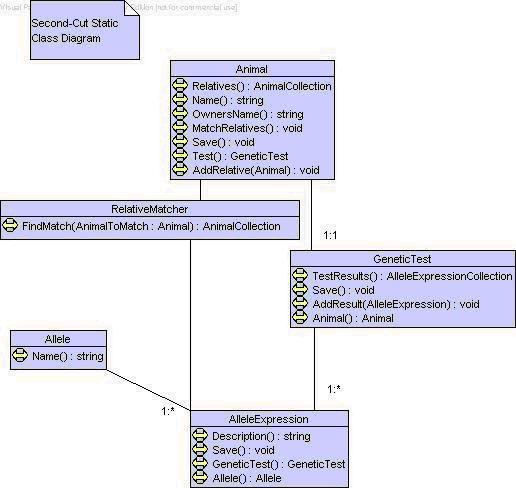
Things to note about this diagram:
-
Possibly the most important thing is that it's a simpler design than the first
cut! This may be due to some assumptions I have made, but is certainly affected
by the fact that I have a clearer idea of the design. The second cut isn't
always clearer than the first, but I quite enjoy it when it is.
-
I am assuming Collection Classes exist, but have not included them explicitly.
They are present as return types for methods.
-
Animal.Relatives() replaces the self-association, although both are real. If
the diagram wasn't showing the methods I would put the self-relation in. I am
50/50 on including it anyway. At the time of printing the diagram I left it
out. Right now I think it should be in. The criterion for making the decision
is: does it improve communication or is it unnecessary (in this context)
detail?
-
TestResult has been merged into AlleleExpression
-
TestResult still lives as a method on GeneticTest
-
RelativeMatcher is still sketchy. It could be folded up as a method of
Animal, but I assume that it's complicated enough that in the interests of
clarity and maintainability it's better off in a separate class. This may go
against YAGNI but in this case,
I think I am (and YAGNI applies to implementation anyway).
Right now, it's not worth any more thought; after all, 'to be supplied' could mean
that the user's going to supply a COM object or something to do it for me!
-
I have assumed that all associations are navigable both ways: a GeneticTest can
give its AlleleExpressions, and each AlleleExpression can give the GeneticTest
it's part of. The navigability will actually come out of the actual implementation:
will the GUI ever need to navigate that way? I don't really know as yet.
-
In busier diagrams I would leave most of these navigation methods
out as being unnecessary detail. The ones I would probably leave are
Animal.Test and GeneticTest.TestResults - the rest are probably clutter.
-
I have decided that on the requirements as they stand there is only one
GeneticTest per Animal, and have firmed up the cardinalities. This means that
GeneticTest could be part of Animal, but a) I'm not sure of this and b) it
seems to me to be sufficiently dissimilar to an Animal as a concept, so I've
left it separate. (Some people insist that all objects/classes must have a
counterpart in the real world, that modelling must match real-world
things. I think this is profoundly wrong for many reasons. However I still find
myself making this sort of decision which appears to be based on what I think
of the real-world. Go figure.)
-
I have assumed that an Allele has a name so that the technician entering the
test results will have some way of identifying which AlleleExpression is which.
Depending on the matching algorithm this may not be necessary. If it's not
necessary then we probably don't need the Allele class.
As things stand, I have a design without any implementation details, but one
that I can actually use to start implementations. To finish it off, I would list the forms or Web
Pages I think I need - there are three:
-
Animal Entry, including GeneticTest and Results
-
Animal Relationships - match and allow the user to select.
-
Enquiry - to show an Animal's relationships.
These may be cut up in different ways - they could all be in one screen, but for
me it would be too busy and complicated. Anyway, this is what I'm going to
propose to the user.
Now it's time to have some discussions with the user to confirm my assumptions
and suggestions - or otherwise.